In today’s world, data is everywhere and the real challenge for businesses is not just gathering it, but making sure it can be stored, processed, and scaled without slowing things down. As companies grow, so does the pressure on their databases. What once managed a few thousand transactions a day may suddenly be expected to handle millions, even billions. That is where techniques like partitioning and sharding come in, offering smarter, more scalable ways to keep databases running smoothly under heavy demand.
Before we get into the best practices, let’s take a moment to unpack what partitioning and sharding actually are, why they matter, and how businesses can put them to use without getting tangled in unnecessary complexity.
Understanding the Scaling Challenge
Traditional monolithic databases work well when data volumes are small. You have one database, one server, one storage location—simple and straightforward.
But as applications grow, several issues start to appear:
- Performance Bottlenecks – A single database server can only handle so many read and write operations per second.
- Storage Limits – Even the most powerful hardware has finite storage capacity.
- High Latency – As data grows, queries take longer, causing application slowdowns.
- Maintenance Complexity – Backups, indexing, and data migrations become riskier and time-consuming.
This is where scaling comes in. Scaling can be done in two ways:
- Vertical Scaling (Scaling Up): Adding more CPU, RAM, or storage to the same database server.
- Horizontal Scaling (Scaling Out): Splitting data across multiple servers, each handling part of the load.
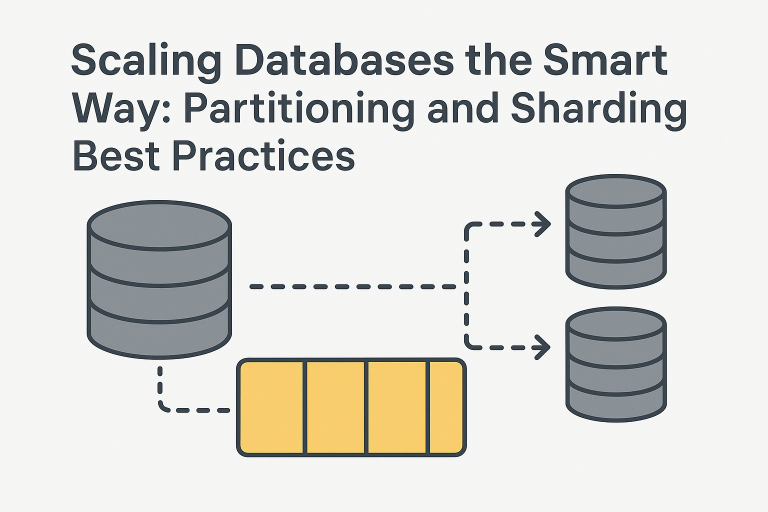
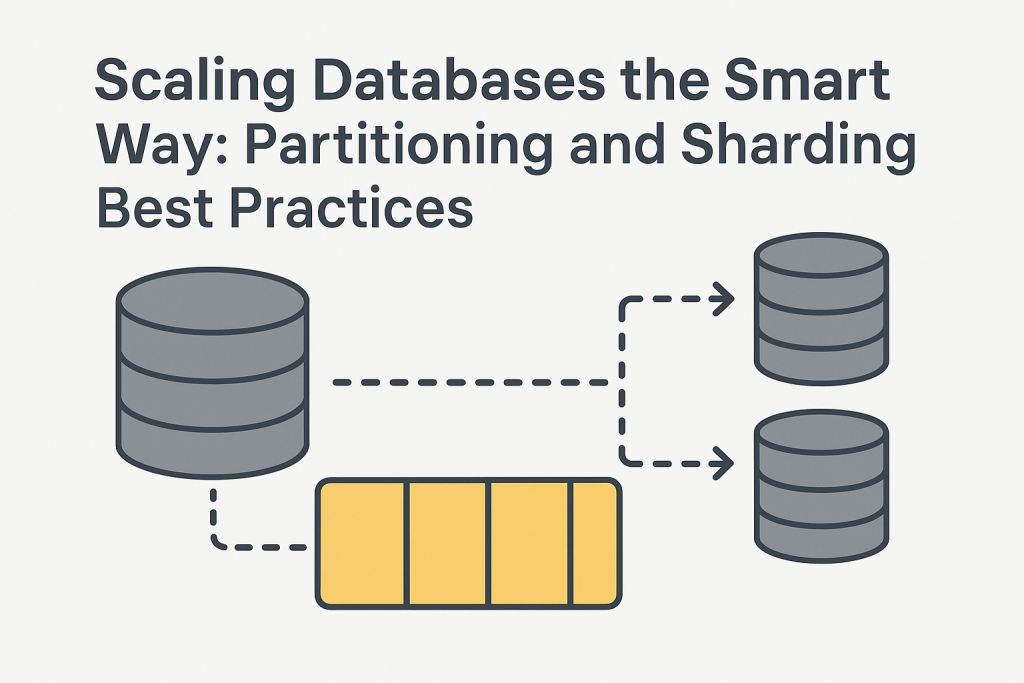
Partitioning and sharding fall under horizontal scaling and form the backbone of modern large-scale database architectures.
Partitioning vs. Sharding: The Core Difference
These two terms are often used interchangeably, but they are not the same thing.
- Partitioning: The process of splitting a large database into smaller, manageable chunks called partitions. Each partition is stored on the same database server but organized in a way that improves performance and maintainability.
- Sharding: Takes partitioning a step further by distributing those partitions across multiple database servers. Each server (or shard) holds a portion of the data, allowing horizontal scaling.
Think of it this way:
- Partitioning is like dividing a single warehouse into sections for better organization.
- Sharding is like splitting the inventory across multiple warehouses to handle more orders at once.
Why Businesses Should Care
For growing enterprises, especially those working with IT consulting services and tech advisors, scaling decisions impact not just performance but the entire digital strategy. Poorly designed databases can slow down operations, increase infrastructure costs, and create bottlenecks for innovation.
A well-thought-out scaling strategy involving partitioning and sharding helps:
- Keep applications fast and responsive.
- Ensure databases stay highly available.
- Simplify maintenance and upgrades.
This is why many companies turn to database design consulting services early in their growth stage—to ensure they choose the right approach from the start.
Types of Partitioning
Before jumping into sharding, it’s essential to understand partitioning since it’s the foundation. There are several partitioning strategies, each with its advantages and best-use cases:
- Horizontal Partitioning (Range Partitioning):
Data is divided based on ranges. For example, all records from January go to one partition, February to another.- Best for: Time-series data, logs, or historical records.
- Vertical Partitioning:
Splits tables by columns. Frequently accessed columns stay together, while rarely used columns move to separate partitions.- Best for: Large tables with hundreds of columns where queries often touch only a few.
- List Partitioning:
Data is divided based on predefined lists of values, such as region = ‘US’, ‘EU’, or ‘Asia’.- Best for: Multi-region applications.
- Hash Partitioning:
A hash function determines the partition. This evenly distributes data but may make range queries harder.- Best for: Workloads where even distribution is critical.
- Composite Partitioning:
Combines two or more partitioning strategies, like range + hash.- Best for: Complex workloads needing both even distribution and logical grouping.
Sharding: Taking Partitioning to the Next Level
Once partitions grow too big for a single server, sharding becomes the logical next step. Each shard runs on a separate server, with its own database instance.
There are two main sharding approaches:
- Key-Based Sharding:
A key (like user ID) determines which shard the data belongs to. This ensures even distribution but requires careful planning to avoid “hot spots” where one shard gets more traffic. - Range-Based Sharding:
Data is divided based on ranges, like users with IDs 1–10000 on shard 1, 10001–20000 on shard 2, and so on. This is easy to implement but can become uneven over time. - Directory-Based Sharding:
A lookup service maintains a mapping of data to shards. This offers flexibility but adds complexity because the directory must always stay in sync.
Best Practices for Partitioning and Sharding
Scaling databases the smart way requires not just technical implementation but strategic foresight. Here are some best practices that IT consulting services often recommend:
1. Design for Scalability from Day One
It’s much easier to plan for partitioning and sharding before the database grows too large. Retroactively applying sharding can involve complex data migration and management services, downtime, and increased costs.
2. Choose the Right Partitioning Key
The partitioning key determines how evenly data is distributed. A poor choice can lead to uneven partitions or overloaded shards.
3. Automate When Possible
Tools like Vitess, Citus (for PostgreSQL), or MongoDB’s native sharding can handle much of the complexity automatically.
4. Monitor and Adjust
Partition sizes and query patterns change over time. Regular monitoring helps prevent hotspots and imbalances.
5. Plan for Failover and Backup
Each shard or partition should have independent backup and failover mechanisms. Losing one shard should not compromise the entire system.
Common Pitfalls and How to Avoid Them
Even with best practices, companies often stumble when implementing partitioning or sharding. Here are a few common mistakes:
- Over-Sharding Early: Splitting data too aggressively creates unnecessary complexity. Start simple and scale as needed.
- Ignoring Future Growth: A partitioning scheme that works today may fail tomorrow if data patterns change.
- Poor Documentation: Without clear documentation, maintenance and onboarding become nightmares.
- Lack of Testing: Always test partitioning and sharding strategies in staging environments before production rollout.
Real-World Example: E-Commerce Platforms
Consider an e-commerce platform growing from thousands to millions of daily transactions. Initially, a single database works fine. But soon:
- Order history queries slow down.
- Inventory updates start lagging.
- Analytics workloads interfere with real-time transactions.
By introducing range partitioning for order history (e.g., partition by month) and sharding based on customer IDs across multiple servers, the platform can:
- Keep recent orders on high-performance shards.
- Archive older data to cheaper storage.
- Run analytics on separate shards without affecting live transactions.
This is where database design consulting services play a crucial role, helping businesses pick the right mix of partitioning and sharding for optimal performance.
The Future of Database Scaling (Beyond AI)
While AI is transforming many areas of IT, the fundamentals of database scaling will continue to rely on sound architecture. Future trends likely to shape partitioning and sharding include:
- Serverless Databases: Automatic scaling without manual sharding decisions.
- Hybrid Cloud Architectures: Combining on-premise and cloud shards for cost and performance optimization.
- Edge Databases: Storing partitions closer to users for ultra-low latency applications.
Even in this evolving landscape, the core principles of smart partitioning and sharding will remain essential for performance and reliability.
Conclusion
As businesses continue to generate and rely on massive amounts of data, the need for systems that can scale efficiently has become more critical than ever. A well-structured approach to database growth is not just about handling larger workloads—it’s about ensuring consistent performance, data integrity, and system reliability even under increasing demands.
Future-ready database systems require more than just technical upgrades; they demand strategic planning, robust architecture, and continuous optimization. By focusing on scalability, organizations can ensure seamless user experiences, maintain operational efficiency, and stay ahead in a competitive digital landscape. The goal is to build systems that are not only capable of supporting current requirements but are also flexible enough to adapt to emerging technologies and evolving business needs.
Ultimately, success lies in designing data infrastructures that can grow gracefully, delivering speed, security, and stability as the organization expands