There is a postmortem I keep coming back to.
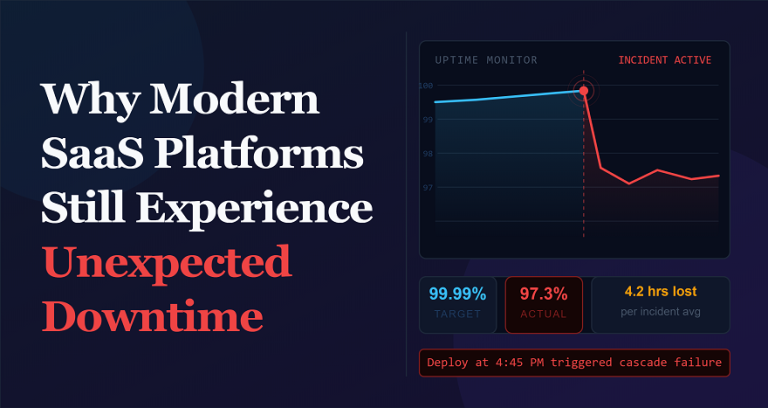
A fintech startup had been ignoring clock drift warnings in their monitoring dashboard for the better part of three months. Not because anyone decided they didn’t matter, more because they showed up as informational alerts, not red ones, and there was always something more urgent on the board. Then one Thursday during a high-volume settlement window, reconciliation broke. Transactions logged out of order. Downstream reporting wrong. A 72-hour manual recovery effort followed, plus an explanatory call to regulators that nobody wanted to have.
The drift had been a few milliseconds. The incident cost weeks.
This pattern repeats across fintech companies, neobanks, payment processors, lending platforms, and it repeats for a reason. It’s not bad luck or poor engineering culture. Understanding fintech infrastructure risk means understanding something structural about what these systems actually are and why small issues inside them don’t stay small.
Why fintech is genuinely different (not just “higher stakes”)
Most places I’ve seen people frame this as a severity argument: fintech is just software, but the consequences are bigger, so treat bugs more seriously. That’s true but incomplete. The more precise thing is that fintech infrastructure sits at the intersection of three domains that each have their own unforgiving logic, and those logics compound on each other.
Money is stateful in a way most data isn’t. A failed social media post can retry silently. A payment that half-executes leaves the system in an inconsistent financial state, one that might need manual reconciliation, regulatory reporting, and customer communication to unwind. You can’t just replay it and hope for the best.
Regulators audit your infrastructure, not just your outcomes. In most software, nobody outside your company cares how your Kubernetes nodes are configured. In fintech, the RBI, FCA, OCC, and their counterparts can require evidence that your infrastructure is auditable, fault-tolerant, and secure. A misconfigured logging pipeline isn’t just a DevOps annoyance. It’s a potential compliance violation sitting quietly in your backlog.
Trust has almost no recovery curve. People tolerate Spotify going down. They do not tolerate their payment app failing during a transaction, and the second time it happens, some of them are gone. There’s no marketing campaign that fully repairs that.
The combination means infrastructure issues that would be logged as low-severity in most systems get multiplied into high-severity risks the moment they enter a fintech context.
The issues that actually cause incidents
These aren’t hypothetical. They’re the patterns behind real fintech deployment failures, the kind that show up in postmortems over and over and almost always trace back to something that was known, logged, and deferred.
Clock drift
I led with this one because it’s the least dramatic-sounding and the most quietly dangerous.
When distributed services aren’t synchronized to a reliable time source, clocks drift. A few milliseconds here, a few seconds there. In most applications, this is harmless background noise. In fintech, it creates ordering ambiguity in transaction logs, breaks idempotency checks, and causes race conditions in settlement processes.
The scenario that breaks things: two microservices processing a payment reversal and the original charge, with clocks out of sync. The reversal gets logged as happening before the charge. Reconciliation breaks. The fix requires finding every affected transaction, manually reconstructing the correct sequence, and explaining to auditors why the logs don’t match the expected order. It’s miserable work.
The fix itself is simple, reliable NTP synchronization and monitoring across all nodes, not just the ones you thought about. The problem is that clock drift doesn’t announce itself dramatically. It accumulates in the informational section of your dashboard until it doesn’t.
Certificate expiry on internal services
Customer-facing certificates get monitored. This is table stakes. The thing that catches teams is the certificates they forgot about, the ones used for service-to-service communication between your payment gateway and fraud detection, or between your core banking system and your ledger.
When these expire, services fail with cryptic errors that look like network issues. Engineers spend hours chasing the wrong root cause while transactions queue and customers call support. The postmortem is always a little embarrassing: the problem was a certificate nobody was watching.
Centralized certificate inventory with automated renewal and expiry alerting across all environments, not just production-facing endpoints, is the fix. The gap is almost always in the certificates you’ve forgotten exist.
Connection pool exhaustion
This one is textbook, and it keeps happening anyway.
Fintech platforms run fine at normal volumes. Then a product launch happens, or a market event drives a traffic spike, and connection pools fill up. New requests can’t acquire connections. Queries queue. Response times climb. Errors start.
What makes it specifically bad in fintech is the cascade: failed queries in a payment processing flow leave transactions in intermediate states. Authorized but not captured. Debited but not credited. Each orphaned transaction is a potential chargeback dispute, customer complaint, or audit finding. Increasing pool sizes helps, but the real fix is circuit breakers, defined fallback behavior for failed transactions, dead letter queues for retry handling, and load testing at peak fintech traffic profiles, not just average daily volumes.
Log retention misconfiguration
This one doesn’t cause any customer-facing outage. Not until a regulator asks for something.
Most fintech companies operate under requirements to retain transaction audit logs for 5-7 years, sometimes longer. The misconfiguration that creates problems isn’t always “we deleted the logs too early.” It’s often “we stored the wrong logs.” Application logs for 30 days in the logging platform, transaction data in the database, assumption made that the database serves as the audit trail. But what regulators often require is event-level logs: what action was taken, by whom, at what timestamp, not just the final state of the database record.
This gets discovered during a regulatory audit or a dispute, at which point the missing logs can’t be recreated. There’s no technical remedy available. The company is non-compliant and the only question is how to manage the consequences.
Third-party dependency sprawl
Every fintech platform accumulates external dependencies: payment processors, identity verification, sanctions screening, credit bureaus, banking rails. Most teams have thought about what happens when individual dependencies fail. The risk that gets less attention is undocumented dependencies added quickly during product development and never hardened.
A fraud detection service calling a third-party enrichment API synchronously in the payment authorization path. An onboarding flow hitting a document verification provider with no timeout configured. A sanctions screening integration that blocks the entire transaction pipeline when it gets rate limited.
Each one starts as a small integration that works fine in normal conditions. Under stress, high load, a provider outage, network instability, it becomes the single point of failure in a system that was otherwise well-designed.
Why these stay small until they don’t
There’s a concept in safety research called drift into failure. Systems don’t fail catastrophically without warning. They drift toward failure through a series of small deviations that individually seem acceptable, even rational. Managing fintech infrastructure risk means recognizing this drift before it compounds, because by the time it’s visible in production, several things have usually already gone wrong together.
Backlog prioritization is the main driver. Issues that don’t cause immediate customer impact get deprioritized in favor of feature work. Individually, each deferral is defensible. Cumulatively, you end up with a system where multiple latent issues coexist, each one waiting for a high-stress event to compound with the others. The clock drift warning from six months ago finally matters when it coincides with the connection pool at 95% during a launch.
Environment parity gaps make it worse. Staging environments that differ meaningfully from production mean issues only surface at scale. The connection pool that handles 10 concurrent staging users fails with 10,000 production ones.
And then there’s the monitoring problem: alert thresholds calibrated to average load miss the patterns that precede failure under peak conditions. If your alert fires at 90% connection pool utilization, and you only see 90% in the ten minutes before failure, you’ve given yourself no time to act. This is part of why teams increasingly invest in 24×7 monitoring services rather than relying on business-hours engineering coverage, because fintech failures don’t wait for the morning standup.
What teams that handle this well actually do
A few things distinguish teams that catch these issues early from those that don’t.
They treat infrastructure health as a product requirement. SLOs cover not just uptime and latency, but certificate validity windows, dependency health scores, connection pool headroom, and log retention coverage. These metrics have owners. They appear in sprint reviews alongside feature work.
They do failure mode analysis before go-live. For every new integration or infrastructure component, they explicitly document what happens when it’s slow, when it fails, and when it fails silently. The answers drive circuit breaker configurations, fallback implementations, and alerting thresholds. Teams that lean on cloud infrastructure management services often have an advantage here, because dedicated infrastructure engineers own this kind of systematic resilience work end-to-end, rather than splitting it between developers who are also shipping features.
They test the edges. Chaos engineering, deliberately injecting failures in controlled environments, reveals assumptions that normal load testing misses. What does your payment flow actually do when the fraud API times out? Is that behavior safe, or does it leave transactions in an intermediate state?
They treat audit infrastructure as a first-class system. Log pipelines, event streaming, and audit trail generation get designed alongside core transaction flows, with explicit requirements for retention, queryability, and completeness. Not bolted on later.
They write down the undocumented. Third-party integrations, manual processes, and system quirks that only live in someone’s head get systematically captured and reviewed. The goal is that when the person who built something is on vacation, someone else can still diagnose what’s wrong with it.
The math that’s easy to get wrong
There’s a calculation teams make when deciding whether to address a latent infrastructure issue: the probability of failure seems low, the cost of fixing it now seems high, features need to ship.
What that calculation tends to underweight is the tail cost specific to fintech when things do go wrong. Engineering time to fix the system is one component. The rest is customer remediation for incorrect charges or failed payments; regulatory notifications and potential fines; legal exposure from affected counterparties; reputational damage that affects acquisition for months afterward; and executive time spent on communication that nobody wanted to write.
A few days of engineering time to fix a connection pool configuration or implement proper certificate monitoring costs a fraction of one serious incident. The asymmetry is real, and teams that have internalized it tend to invest in infrastructure health systematically rather than reactively, because by the time something escalates, the cheap moment to fix it has already passed.
Fintech infrastructure isn’t technically more complicated than other distributed systems. The same fundamentals apply. What’s different is what happens when those fundamentals aren’t followed and how quickly a known, deferred issue can become the root cause of something that takes months to recover from. That’s the core of fintech infrastructure risk: not the catastrophic failures you plan for, but the quiet ones you don’t.
The teams that build reliable fintech systems aren’t the ones who avoid problems. They’re the ones who take problems seriously when they’re still small.